| 研究代表者: | 川口 洋(帝塚山大学・経営学部) |
| 研究分担者: |
上原 邦彦(帝塚山大学・経営学部) 日置 慎治(帝塚山大学・経営学部) |
| 代表者連絡先: | 〒631-8501 奈良市帝塚山7-1-1 帝塚山大学経営学部 Tel. 0742-48-8306 Fax. 0742-46-4994 Email: kawag@tezukayama-u.ac.jp |
| 最終更新日: | 2012年9月13日 |
「宗門改帳」古文書画像データベースを構築する場合,最も長時間の作業を必要とするのが,史料読解,文字データ入力である。 この過程を少しでも自動化できれば,「宗門改帳」読解から人口学的指標算出までの作業時間をいっそう短縮することができる。 そこで古文書文字の自動認識に関する実験を開始した。
本研究では,年齢を表記した16種類の古文書文字(ツ,一,二,三,四,五,六,七,八,九,十,壱,弐,年,拾,廿)を対象 として実験を行った。
漢数字で表記される年齢,牛馬数,世帯規模,持高,家屋規模といった情報の中で,年齢は,結婚年齢,出産年齢,死亡年齢,夫妻の 年齢差,年齢別人口構成,生命表といった人口学的指標を算出する場合,とくに重要な基礎的情報となる。年齢を表記した漢数字の種類は 限定されるうえに,古文書史料には,世帯構成員の名前の下のほぼ固定した位置に記録されているため,セグメンテーションも比較的容易 と予測される。
「文政八年酉年二月 宗旨家別人別分限書上帳 小松川村,寺山村,大久保村,沢入村,寺村」のうち小松川分の史料には, 273種類,3898文字が使われている。このうち今回の実験対象として選択した16種類の文字は,全体の約22%に相当する868文字出現する。 とくに,「弐」,「壱」,「四」は,出現順位が10位以内に入る頻出文字である。加齢などにともない史料作成年次ごとの文字の出現頻度 は変化するが,16種類の文字は常に頻出する。
「宗門改帳」古文書画像データベースに登録されているグレースケールの古文書画像から,実験対象となる文字に外接する枠をかけて手作業で切り出し, 2値化してビットマップ画像として保存する,という手順で採字した。実験対象文字のうち「廿」を除いた15種類の文字を各 200個づつ 採字した。「廿」については66個しか採字できなかった。したがって,実験対象は16種類,3066個の古文書文字である。実験対象とした 16種類の古文書文字は,第1表に示される。
| ツ | 一 | 二 | 三 | 四 | 五 | 六 | 七 |
| 八 | 九 | 十 | 壱 | 弐 | 年 | 拾 | 廿 |
(クリックすると使用した全データを見ることができます。)
77年間にわたる小松川村の「宗門家別人別改書上帳」のうち,寛政4(1792)~寛政12(1800)年の名主は多蔵,享和2(1801) ~文政6(1823)年の名主は太郎兵衛,文政7(1824)~安政4(1857)年の名主は忠左衛門,安政5(1858)~慶応4(1868)年の 名主は忠右衛門である。史料の作成責任者は,この4人であるが,書き役などが書類を書く場合もあるため,実際の執筆者は特定できない。 採字した文字には,複数の人物が書いた文字が含まれていることだけは確実とみられる。
古文書文字は,和紙に毛筆で書かれた手書き文字である。一種類の文字であっても,字形,字体に相当なばらつきがみられる,続け字 (連綿体)が多用されている,文字の太さが多様である,前後の文字などの影響で,文字の大きさが多様であるといった特徴を持っている。 そのため,古文書読解技能を持つ研究者であっても誤読を犯す場合がある。
古文書文字認識の方法として,すでにテンプレート・マッチング,特徴抽出などの方法が提案されている。[1],手書き漢字認識の 方法にまで範囲を広げると,「研究者の数だけ認識手法がある」と梅田三千雄が表現しているほど多様な手法が提案されている[2]。 われわれの研究グループでは,ニューラルネットを用いた手書き文字認識と同様の方法が有効と考えている[3]。この方法を選択した 理由は,特徴抽出による識別処理と比較すると,文字の持っているすべての特徴を取り入れられると期待できることによる。もちろん, 認識率に寄与する顕著な特徴が抽出されれば,入力層PEに加える方針である。
ニューラルネットを用いた手書き文字認識の方法は,次の4段階に大別される。
本研究では,セグメンテーションまでは手作業で行い,濃度計算以下について実験した。濃度特徴計算では,縦横比,大きさの多様な 入力画像を,横10点,縦10の多値データとして正規化した。まず,入力画像の縦横のうち小さい方の両側に空白を付け足して正方形にした。 次いで,標本点の近傍の点に重みを付けながら取り入れるマスクをかけ,10*10に規格化した。この際,文字の重心が中心に来るよう平行 移動させた。マスクの重みは標本点からの距離の関数として,第2表のように設定した。
| 距離 | 1 | 2 | 3 | 4以上 |
| 重み | 1 | 0.5 | 0.1 | 0 |
ニューラルネットの学習過程では,濃度値を入力層からの出力としてバックプロパゲーション法で学習する。これを入力層,中間層, 出力層の3層から構成されるニューラルネットの範疇で実行し,結合係数を出力層各PE(プロセッシングエレメント)の教師付き学習に より求める。入力層は,濃度特徴計算の結果正規化された10*10の100点多値データである。中間層PE数は30とした。出力層には,16種類 の文字それぞれに1ビットを当て16とした。
バックプロパゲーションによる学習を行う場合,認識率が最適となるように,ニューラルネット・パラメータを調整する必要がある。 調整したパラメータは以下の通りである[4]。
パラメータの調整には16種類の文字を各20個づつ学習させ,学習文字と未学習文字を含む実験対象文字全体 に学習結果を適用して認識率(正解率)を求めることにより,パラメータ調整のための実験を行った。
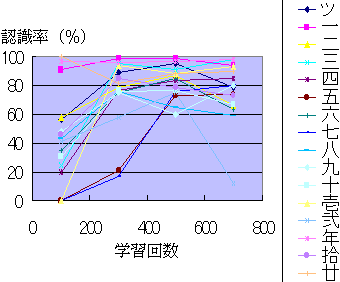
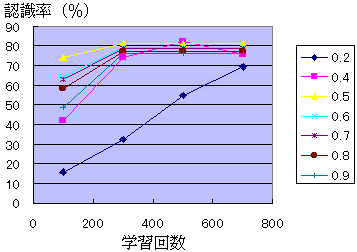
まず,各文字の認識率は,学習回数が増えるにしたがって概ね上昇する(第1図)。しかし,認識率の変化は,文字ごとに異なっている。 第2図によれば,シグモイド関数のパラメータの値に関わらず,認識率は学習回数が増えるにしたがって上昇する。実験を行った0.2,0.4,0.5,0.6,0.7,0.8,0.9の中では, 0.5にした場合の認識率がもっとも高くなる。
(学習回数700回の場合)
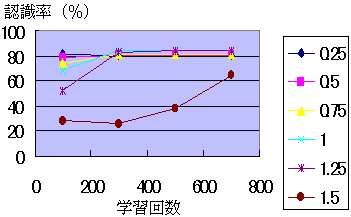
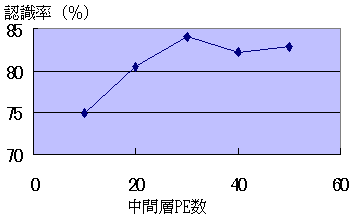
第3図によれば,学習パラメータの値に関わらず,認識率は学習回数が増えるにしたがって上昇する。学習の進行は,1.5と1.25以外の値ではほとんど同じ傾向を示す。 中間層PE数については,30の場合がもっとも良い認識率となる(第4図)。
以上のニューラルネット・パラメータ調整実験の結果から,最適パラメータを次のように決定した。
採字した16種類,3066文字から各80文字(「廿」については33文字)を教師データとして学習させ,上記パラメータを適用して, 残りの未学習文字の認識率を求めた。
第3表によれば,未学習文字1833のなかで正しく認識されたのは1689,認識率はとなった。 文字ごとに見ると,「六」,「七」,「九」,「廿」,「ツ」の認識率は85~89%と比較的低いが,他の文字の認識率は90%を越えている。
| 文字の種類 | 一 | 二 | 三 | 四 | 五 | 六 | 七 | 八 | 九 | 十 | 壱 | 弐 | 拾 | 廿 | ツ | 年 | 合計 |
| 学習文字数 | 80 | 80 | 80 | 80 | 80 | 80 | 80 | 80 | 80 | 80 | 80 | 80 | 80 | 33 | 80 | 80 | 1,233 |
| 未学習文字数 | 120 | 120 | 120 | 120 | 120 | 120 | 120 | 120 | 120 | 120 | 120 | 120 | 120 | 33 | 120 | 120 | 1,833 |
| 正しく認識された文字数 | 120 | 114 | 109 | 110 | 112 | 102 | 104 | 112 | 105 | 114 | 114 | 112 | 112 | 29 | 107 | 113 | 1,689 |
| 認識率(%) | 100 | 95 | 91 | 92 | 93 | 85 | 87 | 93 | 88 | 95 | 95 | 93 | 93 | 88 | 89 | 94 | 92 |
誤認識された文字を正解とともに 別ページにまとめた。
バックプロパゲーションによる学習結果を用いて古文書文字の判読を行なう際,使いやすいユーザー・インターフェースが 必要となる。古文書読解やコンピュータの操作に熟練していない使用者でも簡単に利用できるインターフェースを開発すれば, 史料読解・入力作業の時間を大幅に短縮できる可能性がある。そのため,WINDOWS上に古文書文字判読インターフェースを試作した。 このアプリケーションは,次の手順で利用する。
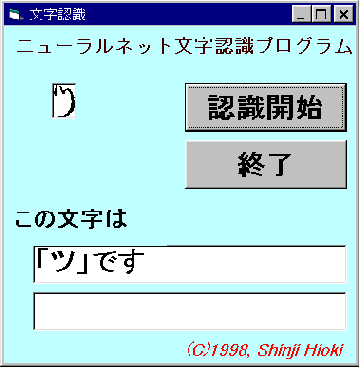
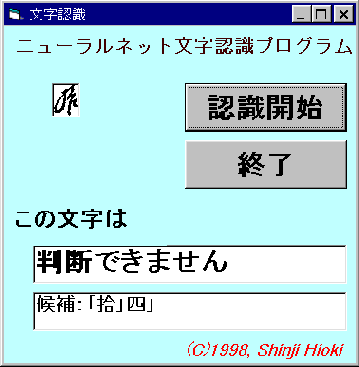
認識結果は第5図のように表示される。判読できない場合には,第6図のように「判読できません」と表示し,古文書文字の候補をあげる。 この機能は以下の利点がある。
江戸時代と現在との間に架橋して,民衆生活の人口学的側面における変貌過程を検討する場合,歴史地理学では人口再生産構造の 時系列的変化と地域差の解明が当面の課題となる。具体的には,持続的人口成長の開始時期と地域差,人口再生産構造を規定する初婚 年齢,出産力,結婚持続期間,平均余命などの地域差の変化とその要因,婚姻や労働を契機とした人口移動の変化などの解明が求められる。 全国を同一の基準で調査した統計資料が存在しない江戸時代においては,各地に保存されている古文書史料を時間的にも地域的にも大量に 収集,蓄積,分析する必要がある。
今回実験した16種類の文字に加えて,石高,金子などの単位を表記した16種類の文字を会わせ,合計 32種類を対象として認識実験を継続する予定である。学習させる文字の種類と個数を増やすと,学習が収束しなくなる可能性が高い。 学習がローカルミニマムに陥るのを避ける多層間の結合係数の最適化法として,シムレーテッド・アニーリング(疑似やきなまし)法を 用いたい。この方法は,多大な計算時間を必要とするので,計算の高速化法が必要となる。高速化法としては,巡回セールスマン問題 (TSP)に適用され,ある程度の正解率が得られる実空間繰り込み群的アプローチなどがあげられる。認識させる文字の種類を増やす場合 には,このような高速化法を導入する必要がある。